
01720 Controlling der IT-Notfallvorsorge
|
Sie wollen in Ihrem Unternehmen mit einfachen Mitteln und wenig Arbeitsaufwand über die vielen verschiedenen Einzelaufgaben der IT-Notfallvorsorge hinweg die Übersicht behalten? Dieser Beitrag soll Ihnen dabei helfen. Mit dem Controlling der IT-Notfallvorsorge werden Sie erkennen, was benötigt wird, was vorhanden ist, in welchem Zustand sich die Notfallhandbücher und die anderen elementaren Bestandteile der IT-Notfallvorsorge befinden und wo es demzufolge Handlungsbedarf gibt. Das vorgestellte Verfahren, ist so flexibel, dass es unabhängig von der Größe des Unternehmens anwendbar ist. Arbeitshilfen: von: |
1 Einführung
IT-Notfallvorsorge
Die IT-Notfallvorsorge ist die Disziplin des Managements der Informationsverarbeitung (IT) in einem Unternehmen, die Notfallpläne entwickelt und pflegt. Diese Pläne werden benötigt, wenn es infolge eines Störfalls zu einem Ausfall kritischer IT Services kommt. Sie beschreiben den gesamten notwendigen Weg bis hin zum Wiederanlauf dieser Services, einschließlich Erfassung der Gesamtproblemsituation, Etablierung von Workarounds, Alarmierungen, Personalmanagement für die Notfalllage, Einrichtung eines Notbetriebs, Wiederbeschaffung verloren gegangener Komponenten. Am Schluss sind alle IT Services vollständig wiederhergestellt.
Die IT-Notfallvorsorge ist die Disziplin des Managements der Informationsverarbeitung (IT) in einem Unternehmen, die Notfallpläne entwickelt und pflegt. Diese Pläne werden benötigt, wenn es infolge eines Störfalls zu einem Ausfall kritischer IT Services kommt. Sie beschreiben den gesamten notwendigen Weg bis hin zum Wiederanlauf dieser Services, einschließlich Erfassung der Gesamtproblemsituation, Etablierung von Workarounds, Alarmierungen, Personalmanagement für die Notfalllage, Einrichtung eines Notbetriebs, Wiederbeschaffung verloren gegangener Komponenten. Am Schluss sind alle IT Services vollständig wiederhergestellt.
Vorsorgemaßnahmen wirken begrenzt
Mit präventiv wirkenden Maßnahmen zur Notfallvorsorge, zum Beispiel Redundanz von Rechenzentren und Systemen oder Backup von Daten, sollen Serviceausfälle verhindert werden, aber das ist nur begrenzt möglich. Wenn es trotz solcher Maßnahmen zu einem Serviceausfall kommt, muss die IT in der Lage sein, den Wiederanlauf in ausreichender Zeit durchzuführen, nämlich ehe der Ausfall zu einem kritischen Schaden führt. Das wird nicht gelingen, wenn der Wiederanlauf bzw. Wiederaufbau kompliziert ist, es sei denn, die IT hat sich im Voraus eine erfolgversprechende Strategie (Notfallplan bzw. Disaster Recovery Plan) überlegt und in Form eines Notfallhandbuchs dokumentiert. Außerdem wurden die nötigen Mittel zur Umsetzung der Strategie, zum Beispiel Ersatzteile, beschafft. Mit IT-Notfallvorsorge ist genau das gemeint.
Mit präventiv wirkenden Maßnahmen zur Notfallvorsorge, zum Beispiel Redundanz von Rechenzentren und Systemen oder Backup von Daten, sollen Serviceausfälle verhindert werden, aber das ist nur begrenzt möglich. Wenn es trotz solcher Maßnahmen zu einem Serviceausfall kommt, muss die IT in der Lage sein, den Wiederanlauf in ausreichender Zeit durchzuführen, nämlich ehe der Ausfall zu einem kritischen Schaden führt. Das wird nicht gelingen, wenn der Wiederanlauf bzw. Wiederaufbau kompliziert ist, es sei denn, die IT hat sich im Voraus eine erfolgversprechende Strategie (Notfallplan bzw. Disaster Recovery Plan) überlegt und in Form eines Notfallhandbuchs dokumentiert. Außerdem wurden die nötigen Mittel zur Umsetzung der Strategie, zum Beispiel Ersatzteile, beschafft. Mit IT-Notfallvorsorge ist genau das gemeint.
Begriff
Der Begriff IT-Notfallvorsorge ist wie viele Fachbegriffe der IT nicht eindeutig. Alternativ werden oft Begriffe wie IT Continuity, IT Service Continuity, Disaster Recovery und viele andere meist englische Begriffe, mal mit, mal ohne Zusatz des Begriffs Management, benutzt. In diesem Beitrag wird immer von IT-Notfallvorsorge die Rede sein. Damit wird auch betont, dass es um die Services der IT geht.
Der Begriff IT-Notfallvorsorge ist wie viele Fachbegriffe der IT nicht eindeutig. Alternativ werden oft Begriffe wie IT Continuity, IT Service Continuity, Disaster Recovery und viele andere meist englische Begriffe, mal mit, mal ohne Zusatz des Begriffs Management, benutzt. In diesem Beitrag wird immer von IT-Notfallvorsorge die Rede sein. Damit wird auch betont, dass es um die Services der IT geht.
BCM
IT-Notfallmanagement ist ein Spezialfall des allgemeinen, übergeordneten Begriffs Business Continuity Management (BCM). BCM (siehe auch Kap. 01710) adressiert die kritischen Geschäftsprozesse und mögliche Auswirkungen, wenn diese ausfallen. Dabei geht BCM von verschiedenen Szenarien aus, von denen eines der Ausfall der IT ist. Geschäftsprozesse werden heutzutage fast immer mittels IT abgebildet oder von dieser unterstützt, so dass IT-Notfallmanagement ein wichtiger Block innerhalb von BCM ist.
IT-Notfallmanagement ist ein Spezialfall des allgemeinen, übergeordneten Begriffs Business Continuity Management (BCM). BCM (siehe auch Kap. 01710) adressiert die kritischen Geschäftsprozesse und mögliche Auswirkungen, wenn diese ausfallen. Dabei geht BCM von verschiedenen Szenarien aus, von denen eines der Ausfall der IT ist. Geschäftsprozesse werden heutzutage fast immer mittels IT abgebildet oder von dieser unterstützt, so dass IT-Notfallmanagement ein wichtiger Block innerhalb von BCM ist.
IT-Notfallvorsorge ist eine sehr komplexe Aufgabe. Sie besteht aus vielen Teildisziplinen, die jeweils ganz unterschiedliche Arbeitsergebnisse liefern sollen. BCM-Standards wie ISO 22301 [1] (s. a. Kap. 07342) bemühen sich, Aufgaben und Resultate der IT-Notfallvorsorge innerhalb des allgemeinen Notfallmanagements zu definieren und zu vereinheitlichen, doch es ist das Wesen von Standards, eher zu sagen, was gemacht werden muss als wie. Dieser Beitrag will dieses Problem nicht lösen. Es wird zum Beispiel nur sehr grob beschrieben, wie ein Notfallhandbuch aussehen sollte, und Gleiches gilt auch für andere wichtige Arbeiten der IT-Notfallvorsorge und deren Resultate, etwa die Durchführung von Risikoanalysen. Stattdessen wird der Frage nachgegangen, wie ein Unternehmen mit einfachen Mitteln und wenig Arbeitsaufwand über alle Einzelaufgaben der IT-Notfallvorsorge hinweg die Übersicht behalten kann. Durch das Controlling der IT-Notfallvorsorge soll bekannt sein, was benötigt wird, was vorhanden ist, in welchem Zustand sich die Notfallhandbücher und die anderen elementaren Bestandteile der IT-Notfallvorsorge befinden, und wo es demzufolge Handlungsbedarf gibt. Dafür wird ein Verfahren vorgestellt, das so flexibel ist, dass es unabhängig von der Größe des Unternehmens anwendbar ist.
Controlling der IT-Notfallvorsorge
Viele Menschen im Unternehmen müssen aufgrund ihrer Position oder einer ihnen zugewiesenen Rolle dafür Sorge tragen, dass die IT auf eventuelle Notfälle gut vorbereitet ist. Neben der Leitung der IT, dem Information Security Officer, dem Datenschutzbeauftragten, der Geschäftsführung und der Revision gehört dazu auch eine spezielle IT-Notfallvorsorgeorganisation mit einem Notfallbeauftragten an der Spitze. Ihnen allen fällt es schwer, die Übersicht zu behalten, zu wissen, worauf man bauen kann, und ebenso, wo es Defizite gibt, die es abzustellen gilt, zum Beispiel fehlende, veraltete oder aus anderen Gründen unbrauchbare Notfallhandbücher. Das zu ändern ist die Aufgabe des Controllings der IT-Notfallvorsorge.
Viele Menschen im Unternehmen müssen aufgrund ihrer Position oder einer ihnen zugewiesenen Rolle dafür Sorge tragen, dass die IT auf eventuelle Notfälle gut vorbereitet ist. Neben der Leitung der IT, dem Information Security Officer, dem Datenschutzbeauftragten, der Geschäftsführung und der Revision gehört dazu auch eine spezielle IT-Notfallvorsorgeorganisation mit einem Notfallbeauftragten an der Spitze. Ihnen allen fällt es schwer, die Übersicht zu behalten, zu wissen, worauf man bauen kann, und ebenso, wo es Defizite gibt, die es abzustellen gilt, zum Beispiel fehlende, veraltete oder aus anderen Gründen unbrauchbare Notfallhandbücher. Das zu ändern ist die Aufgabe des Controllings der IT-Notfallvorsorge.
Hauptaufgaben des Controlling
Wie jedes Controlling hat es drei Hauptaufgaben:
Wie jedes Controlling hat es drei Hauptaufgaben:
| • | Fakten beschaffen |
| • | Bewertung der Fakten vornehmen |
| • | Handlungsbedarf erkennen und Maßnahmen initiieren |
Hier werden vor allem die beiden ersten Punkte behandelt. Es wird beschrieben, welche Fakten ermittelt werden müssen und wo sie herkommen. Es wird erläutert, wie die Fakten zu bewerten sind und was aus der Bewertung für die einzelnen Prozessschritte folgt.
Das Thema „Initiierung von Maßnahmen” wird hier hingegen nicht im Detail betrachtet. Welche Maßnahmen nötig sind, ergibt sich jeweils unmittelbar aus den Bewertungen. Wird etwa festgestellt, dass etwas fehlt, besteht die Maßnahme darin, das Fehlende zu erzeugen oder zu beschaffen. Ist etwas schlecht, muss es überarbeitet werden. Die Nachverfolgung der Umsetzung von beschlossenen Maßnahmen schließlich sollte eine Standardaufgabe der IT sein.
2 Prozess der IT-Notfallvorsorge
Der rote Faden
Populäre Vorschläge für den Aufbau einer IT-Notfallvorsorge, zum Beispiel der des Bundesamtes für Sicherheit in der Informationstechnik (BSI) [2], sind wichtige Hilfsmittel für jeden, der mit dieser Aufgabe befasst ist. Sie beschreiben zahlreiche sinnvolle Einzelaufgaben und geben Hinweise zur Umsetzung. Gerade dann, wenn die IT-Notfallvorsorge ganz am Anfang steht, ist oft nicht klar, was der sinnvolle erste Schritt ist und was danach logischerweise in welcher Reihe folgen sollte. Wenn jedoch ein Weg nicht vom Start bis zum Ziel bekannt ist, kann auch nicht bestimmt werden, wie nahe das Ziel ist bzw. wie weit der restliche Weg noch ist und mit wie viel Aufwand noch zu rechnen ist. Damit wird das ganze Projekt unkalkulierbar. Ein Scheitern droht. Ein Controlling will genau das ändern, und deshalb muss zunächst der rote Faden gesponnen werden. Um es mit einem Wort zu sagen, das viele der handelnden Personen in der Organisation fürchten und wegen seiner möglichen bürokratischen Folgen gar verachten: der Prozess der IT-Notfallvorsorge muss definiert sein. Wie der Prozess aussehen kann, zeigt Abbildung 1.
Populäre Vorschläge für den Aufbau einer IT-Notfallvorsorge, zum Beispiel der des Bundesamtes für Sicherheit in der Informationstechnik (BSI) [2], sind wichtige Hilfsmittel für jeden, der mit dieser Aufgabe befasst ist. Sie beschreiben zahlreiche sinnvolle Einzelaufgaben und geben Hinweise zur Umsetzung. Gerade dann, wenn die IT-Notfallvorsorge ganz am Anfang steht, ist oft nicht klar, was der sinnvolle erste Schritt ist und was danach logischerweise in welcher Reihe folgen sollte. Wenn jedoch ein Weg nicht vom Start bis zum Ziel bekannt ist, kann auch nicht bestimmt werden, wie nahe das Ziel ist bzw. wie weit der restliche Weg noch ist und mit wie viel Aufwand noch zu rechnen ist. Damit wird das ganze Projekt unkalkulierbar. Ein Scheitern droht. Ein Controlling will genau das ändern, und deshalb muss zunächst der rote Faden gesponnen werden. Um es mit einem Wort zu sagen, das viele der handelnden Personen in der Organisation fürchten und wegen seiner möglichen bürokratischen Folgen gar verachten: der Prozess der IT-Notfallvorsorge muss definiert sein. Wie der Prozess aussehen kann, zeigt Abbildung 1.

Natürlich gibt es Alternativen, und es wird ausdrücklich dazu ermuntert, den Prozess der IT-Notfallvorsorge entsprechend den eigenen Anforderungen und Rahmenbedingungen zu gestalten. Die hier im Weiteren folgenden Vorschläge beziehen sich allerdings auf den Prozess in Abbildung 1.
Für das Verständnis der nachfolgend beschriebenen Methodik des Controllings der IT-Notfallvorsorge sind die nun folgenden Hinweise wichtig.
Notfallbeauftragter
Es muss im Unternehmen eine Person geben, die für die IT-Notfallvorsorge in übergeordneter Funktion zuständig ist. In Anlehnung an die Vorschläge in Standards soll diese Rolle Notfallbeauftragter (für IT Services) genannt werden.
Es muss im Unternehmen eine Person geben, die für die IT-Notfallvorsorge in übergeordneter Funktion zuständig ist. In Anlehnung an die Vorschläge in Standards soll diese Rolle Notfallbeauftragter (für IT Services) genannt werden.
Der Notfallbeauftragte wird die wenigsten Arbeiten in der IT-Notfallvorsorge selbst durchführen. Aber er sorgt dafür, dass alles, was gemäß dem Konzept der IT-Notfallvorsorge geplant ist, von den jeweils Zuständigen auch getan wird.
Pragmatische Notfallvorsorge
Viele der von der IT-Notfallvorsorge genutzten Teilprozesse, zum Beispiel die Risikoanalyse, sind in einer idealen IT-Organisation Standard und erfüllen dort Aufgaben, die weit über das hinausgehen, was die IT-Notfallvorsorge braucht. Entsprechend komplex und aufwändig können sie sein. Wenn es diese Methoden und Verfahren jedoch nicht bereits gibt und sie im Kontext der IT-Notfallvorsorge eingeführt werden müssen, können sie sehr schlank gehalten werden. Das gilt etwa für die Identifikation von Risiken, die Sicherheitsziele wie Vertraulichkeit und Datenschutz betreffen. Die Notfallvorsorge interessiert sich nur für die Verfügbarkeit. Natürlich ist keinem Unternehmen anzuraten, sich ausschließlich um die IT-Notfallvorsorge zu kümmern. Für die übergeordnete Sicht der Informationssicherheit ist in der klassischen Organisation jedoch eine andere Rolle zuständig, nämlich der Informationssicherheitsbeauftragte.
Viele der von der IT-Notfallvorsorge genutzten Teilprozesse, zum Beispiel die Risikoanalyse, sind in einer idealen IT-Organisation Standard und erfüllen dort Aufgaben, die weit über das hinausgehen, was die IT-Notfallvorsorge braucht. Entsprechend komplex und aufwändig können sie sein. Wenn es diese Methoden und Verfahren jedoch nicht bereits gibt und sie im Kontext der IT-Notfallvorsorge eingeführt werden müssen, können sie sehr schlank gehalten werden. Das gilt etwa für die Identifikation von Risiken, die Sicherheitsziele wie Vertraulichkeit und Datenschutz betreffen. Die Notfallvorsorge interessiert sich nur für die Verfügbarkeit. Natürlich ist keinem Unternehmen anzuraten, sich ausschließlich um die IT-Notfallvorsorge zu kümmern. Für die übergeordnete Sicht der Informationssicherheit ist in der klassischen Organisation jedoch eine andere Rolle zuständig, nämlich der Informationssicherheitsbeauftragte.
Die IT-Notfallvorsorge kann nicht alle Defizite der IT-Organisation beseitigen. Sie kann und will nicht alle Analysen durchführen, die längst hätten durchgeführt werden müssen, und alle Dokumente liefern, die längst hätten geliefert werden müssen. Sie soll sich in erster Linie um die eigenen Probleme kümmern. Das Controlling, das hier vorgeschlagen wird, wird sich dementsprechend nur mit Fragen befassen, die für die IT-Notfallvorsorge wichtig sind.
Wenn alles Unnötige konsequent außen vor gelassen wird, dann erfordert das IT-Notfall-Controlling, geschickt organisiert, nur geringen Aufwand. Dafür ist es wichtig, bei den erforderlichen Analysen und Bewertungen einen vernünftigen Grad der Detaillierung zu wählen. Manches Managementsystem scheitert, weil sich die angewandten Methoden in pseudowissenschaftlicher Genauigkeit verlieren. Für das Risikomanagement eines Unternehmens mag es interessant sein, wie hoch genau ein Einzelrisiko ist, und es möchte die Auskunft am liebsten in Euro ausgedrückt bekommen. Für die IT-Notfallvorsorge reicht es jedoch völlig, zu erkennen, ob das Risiko kritisch ist oder nicht. Entsprechend grob kann die Methode der Risikoanalyse hier sein. Ein einfaches „ja” oder „nein” als Auskunft genügt.
80:20-Regel
Pragmatismus bedeutet vielfach, die goldene 80:20-Regel zu befolgen: 80 % der Ergebnisse lassen sich mit 20 % des Gesamtaufwands erreichen. Es ist häufig besser, sich an dem zu orientieren, was möglich ist, etwa im Hinblick auf das Budget, das der Notfallbeauftragte zur Verfügung hat, als das anzustreben, was im Sinn der reinen Lehre maximal wünschenswert wäre. Deshalb werden nachfolgend die Metriken bewusst sehr einfach gehalten, auf das Risiko hin, nicht jeden Spezialfall individuell zu behandeln, aber mit dem Lohn, für den großen Rest in kurzer Zeit zu guten Notfallplänen zu kommen. Es kann zum Beispiel gar nicht das Ziel sein, für alle IT Services und alle denkbaren Ausfallszenarien ausformulierte Notfallhandbücher zu haben, das kann so gut wie keine IT-Organisation der Welt leisten. Aber es sollte das Ziel sein, für die kritischsten 80 % der IT Services und die kritischsten 80 % der Ausfallszenarien solche Pläne zu haben.
Pragmatismus bedeutet vielfach, die goldene 80:20-Regel zu befolgen: 80 % der Ergebnisse lassen sich mit 20 % des Gesamtaufwands erreichen. Es ist häufig besser, sich an dem zu orientieren, was möglich ist, etwa im Hinblick auf das Budget, das der Notfallbeauftragte zur Verfügung hat, als das anzustreben, was im Sinn der reinen Lehre maximal wünschenswert wäre. Deshalb werden nachfolgend die Metriken bewusst sehr einfach gehalten, auf das Risiko hin, nicht jeden Spezialfall individuell zu behandeln, aber mit dem Lohn, für den großen Rest in kurzer Zeit zu guten Notfallplänen zu kommen. Es kann zum Beispiel gar nicht das Ziel sein, für alle IT Services und alle denkbaren Ausfallszenarien ausformulierte Notfallhandbücher zu haben, das kann so gut wie keine IT-Organisation der Welt leisten. Aber es sollte das Ziel sein, für die kritischsten 80 % der IT Services und die kritischsten 80 % der Ausfallszenarien solche Pläne zu haben.
3 Notfall-Monitor
In jedem Controlling werden Fakten zusammengetragen, korreliert und aggregiert, bewertet und schließlich in Berichten präsentiert. Schon aufgrund der Menge der Daten wird dafür ein Werkzeug benötigt, für die Erstellung ansprechender und aussagekräftiger Berichte sowieso. Dieses Werkzeug wird hier Notfall-Monitor genannt.
Software
Für die Art von Controlling, die hier vorgeschlagen wird, reicht ein Spreadsheet, wie es mit üblicher Office-Software bearbeitet werden kann. Für Aufgaben des allgemeinen Business Continuity Managements (BCM) wird am Markt zum Teil sehr leistungsstarke, aber auch entsprechend teure kommerzielle Software angeboten. Wenn das BCM eine gewisse Komplexität erreicht, mögen solche Applikationen nützlich sein. Zu Beginn genügen Anwendungen wie OpenOffice Calc, Microsoft Excel oder Apple Numbers. In überschaubaren IT-Organisationen wird das sogar auf Dauer ausreichen.
Für die Art von Controlling, die hier vorgeschlagen wird, reicht ein Spreadsheet, wie es mit üblicher Office-Software bearbeitet werden kann. Für Aufgaben des allgemeinen Business Continuity Managements (BCM) wird am Markt zum Teil sehr leistungsstarke, aber auch entsprechend teure kommerzielle Software angeboten. Wenn das BCM eine gewisse Komplexität erreicht, mögen solche Applikationen nützlich sein. Zu Beginn genügen Anwendungen wie OpenOffice Calc, Microsoft Excel oder Apple Numbers. In überschaubaren IT-Organisationen wird das sogar auf Dauer ausreichen.
Daten im Notfall-Monitor
Der Begriff Notfall-Monitor könnte die Vorstellung auslösen, dass es sich dabei um ein sehr komplexes Gebilde handelt. Das muss nicht so sein. Im einfachsten Fall ist der Notfall-Monitor nur eine große Tabelle und sieht so aus, wie es die Abbildung 2 andeutet.
Der Begriff Notfall-Monitor könnte die Vorstellung auslösen, dass es sich dabei um ein sehr komplexes Gebilde handelt. Das muss nicht so sein. Im einfachsten Fall ist der Notfall-Monitor nur eine große Tabelle und sieht so aus, wie es die Abbildung 2 andeutet.
Ein einfacher Rumpf einer solchen Excel-Tabelle ist hier als Arbeitshilfe beigefügt. Diese orientiert sich an den hier im Folgenden vorgestellten Elementen. Die Tabelle kann nur eine Orientierung geben und muss an die tatsächlichen Anforderungen im konkreten Fall angepasst werden. Berichte oder Auswertefunktionen sind nicht enthalten, da diese in besonderem Maße von betrieblichen Gegebenheiten abhängig sind.[ 01720_a.xlsx]
01720_a.xlsx]
01720_a.xlsx]
In den folgenden Abschnitten wird beschrieben, welche Informationen in dieser Tabelle enthalten sein sollten und welche Aussagekraft sie im Sinn des Controlling-Gedankens haben. Natürlich kann die Tabelle bzw. das Werkzeug der Wahl um beliebige weitere Angaben ergänzt werden. Es ist aber in jedem Einzelfall kritisch zu hinterfragen, ob es nützlich ist, über diese Zusatzinformation zu verfügen. Der Versuchung, über eine möglichst breite Datensammlung verfügen zu wollen, ist wegen des mit der Datenpflege verbundenen Arbeitsaufwands unbedingt zu widerstehen. Überdies ist der Erkenntnisgewinn in vielen Fällen gering. Tatsächlich dürften die hier beschriebenen Einzelinformationen, nachfolgend mit Daten im Notfall-Monitor gekennzeichnet, für ein wirksames Controlling der IT-Notfallvorsorge völlig ausreichen.
Datenpflege
Unabhängig von der eingesetzten Software müssen die Daten im Notfall-Monitor gepflegt werden. Das beginnt mit der erstmaligen Erhebung und Erfassung. Anschließend bedarf es einer regelmäßigen Überprüfung und Aktualisierung. Dies ist die Aufgabe des Notfallbeauftragten, und es ist wahrscheinlich, dass dies weitgehend manuell erfolgen wird. Wenn es zum Beispiel interessant ist, für welche IT Services es Notfallhandbücher gibt und wie aktuell diese sind, dann könnte die Information in einem entsprechend organisierten System vielleicht automatisch ermittelt werden. Agenten, die Dateiablagen durchsuchen und aus Files Informationen wie das Datum der letzten Änderung ermitteln, sind prinzipiell denkbar. Ein solches System wäre aber technisch anspruchsvoll, nicht zuletzt, weil es kaum eine IT-Organisation schafft, über alle Themen und Fachteams hinweg eine einheitliche Dokumentenablage zu etablieren. Zudem würde die automatische Auswertung ein Maß an Disziplin bei der Formatierung und der Ablage zentraler Dokumente voraussetzen, das in einer durchschnittlichen IT-Organisation unerreichbar ist. Qualitative Aussagen, etwa „Wie gut ist ein Recovery Plan?” oder „In welchem Umfang werden die Verfügbarkeitszusagen der IT an die User erfüllt?” sind gar nicht automatisiert zu ermitteln.
Unabhängig von der eingesetzten Software müssen die Daten im Notfall-Monitor gepflegt werden. Das beginnt mit der erstmaligen Erhebung und Erfassung. Anschließend bedarf es einer regelmäßigen Überprüfung und Aktualisierung. Dies ist die Aufgabe des Notfallbeauftragten, und es ist wahrscheinlich, dass dies weitgehend manuell erfolgen wird. Wenn es zum Beispiel interessant ist, für welche IT Services es Notfallhandbücher gibt und wie aktuell diese sind, dann könnte die Information in einem entsprechend organisierten System vielleicht automatisch ermittelt werden. Agenten, die Dateiablagen durchsuchen und aus Files Informationen wie das Datum der letzten Änderung ermitteln, sind prinzipiell denkbar. Ein solches System wäre aber technisch anspruchsvoll, nicht zuletzt, weil es kaum eine IT-Organisation schafft, über alle Themen und Fachteams hinweg eine einheitliche Dokumentenablage zu etablieren. Zudem würde die automatische Auswertung ein Maß an Disziplin bei der Formatierung und der Ablage zentraler Dokumente voraussetzen, das in einer durchschnittlichen IT-Organisation unerreichbar ist. Qualitative Aussagen, etwa „Wie gut ist ein Recovery Plan?” oder „In welchem Umfang werden die Verfügbarkeitszusagen der IT an die User erfüllt?” sind gar nicht automatisiert zu ermitteln.
Aufgrund dessen lautet der Vorschlag, die Datenpflege komplett manuell durchzuführen. Der Notfallbeauftragte schaut sich von Zeit zu Zeit seine Informationsquellen an und überträgt wichtige Daten in sein Werkzeug. Konzentriert sich das Controlling auf das Wesentliche, nämlich die Daten, die wirklich benötigt werden, um die IT-Notfallvorsorge effektiv zu steuern, ist der mit der manuellen Datenpflege verbundene Arbeitsaufwand gering.
4 Servicekatalog
Natürlich weiß jeder, dass es unvernünftig ist, nach einer Lösung zu suchen, wenn das Problem bestenfalls vage beschrieben werden kann, und doch wird immer wieder genau das gemacht. Die IT-Notfallvorsorge soll dazu beitragen, kritische IT Services abzusichern. Dabei ist fast immer unklar, was denn die Services der IT sind. Nicht selten ist nicht einmal eindeutig, was IT ist.
Liste der IT Services
Die erste Aufgabe der IT-Notfallvorsorge und somit auch das erste, was im Controlling der IT-Notfallvorsorge überwacht werden muss, ist die Pflege des Servicekatalogs der IT. Das ist eine Liste derjenigen Leistungen, die der Bereich IT für seine internen und externen Kunden, also die Nutzer der IT Services, erbringt. Zu den absoluten Grundregeln aller Aktivitäten wird nämlich ab sofort gehören: Was immer es ist – wenn es nicht auf der Liste der IT Services erscheint, wird es dafür auch keine Notfallvorsorge geben.
Die erste Aufgabe der IT-Notfallvorsorge und somit auch das erste, was im Controlling der IT-Notfallvorsorge überwacht werden muss, ist die Pflege des Servicekatalogs der IT. Das ist eine Liste derjenigen Leistungen, die der Bereich IT für seine internen und externen Kunden, also die Nutzer der IT Services, erbringt. Zu den absoluten Grundregeln aller Aktivitäten wird nämlich ab sofort gehören: Was immer es ist – wenn es nicht auf der Liste der IT Services erscheint, wird es dafür auch keine Notfallvorsorge geben.
Die Liste der IT Services ergibt sich aus den kritischen Geschäftsprozessen einer Organisation. Alle IT Services, die von kritischen Geschäftsprozessen genutzt werden, sind Bestandteil der IT-Notfallvorsorge. Man kann entweder direkt eine Liste der kritischen Geschäftsprozesse erstellen oder aber auf der Ebene von Produkten und Dienstleistungen beginnen und sich die Frage stellen, welche Geschäftsprozesse und IT Services benötigt werden, um das Produkt bzw. die Dienstleistung anzubieten.
Definition IT Services
Was ist eigentlich ein IT Service bezogen auf die IT-Notfallvorsoge? Dafür gibt es keine klaren Regeln. Im Wesentlichen dürften aber folgende Leistungsarten als IT Service anzusehen sein:
Was ist eigentlich ein IT Service bezogen auf die IT-Notfallvorsoge? Dafür gibt es keine klaren Regeln. Im Wesentlichen dürften aber folgende Leistungsarten als IT Service anzusehen sein:
| • | Betrieb von Applikationen einschließlich Verwaltung ihrer Daten |
| • | Bereitstellung und Betrieb von Endgeräten wie PCs/Notebook, Tablets, Smartphones und anderen mobilen Geräten |
| • | Bereitstellung und Betrieb anderer Geräte, mit denen Nutzer direkt arbeiten, zum Beispiel Drucker oder Geräte der Haustechnik |
| • | Bereitstellung und Betrieb von Plattformen wie Server, Netzwerke und Speicher; eine Plattform ist ein System, das für die Erbringung eines IT Service nötig ist, mit dem ein Nutzer aber nicht unmittelbar in Berührung kommt und das deswegen oft gar nicht von ihm wahrgenommen wird. |
| • | IT-Dienstleistungen; das können Dienste sein, die als integrierter Bestandteil der vorgenannten Services angesehen werden könnten, zum Beispiel Backup für Speichersysteme oder die Reparatur von Endgeräten; hinzukommen eigenständige IT Services wie User Help Desk oder Projekt-Support. |
Daten im Notfall-Monitor
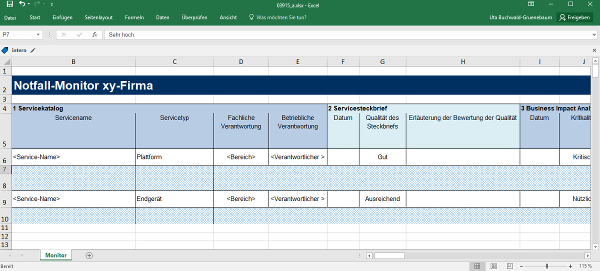
Der Servicekatalog muss im einfachsten Fall nicht mehr sein als die Liste der Namen der Services (vgl. Tabelle 1). Hilfreich kann es sein, die Services in Typen einzuteilen, wie sich im Weiteren noch zeigen wird.
Der Servicekatalog muss im einfachsten Fall nicht mehr sein als die Liste der Namen der Services (vgl. Tabelle 1). Hilfreich kann es sein, die Services in Typen einzuteilen, wie sich im Weiteren noch zeigen wird.
Tabelle 1: Elemente des Servicekatalogs
Spalte | Information | Beschreibung |
|---|---|---|
1A | Servicename | Bezeichnung des Service |
1B | Servicetyp | Applikation, Endgerät, Plattform, Dienstleistung ... |
Service Manager
Wie granular bzw. komplex ein Service ist, kann individuell festgelegt werden. Ob der Service „Server” zum Beispiel auch das Betriebssystem und die Middleware einschließt oder ob statt eines einzelnen Servers eine Serverfarm betrachtet wird, ist aus Sicht der IT-Notfallvorsorge erst einmal unerheblich. Hauptsache ist, dass am Ende die Service-Liste alles abdeckt, worum sich die IT-Notfallvorsorge kümmern soll. Ein Kriterium hilft jedoch, zu prüfen, ob ein Service sinnvoll abgegrenzt ist. Es muss möglich sein, eine Person zu benennen, die für den Service in Gänze Verantwortung trägt. Solche Personen werden gerne Service Manager genannt.
Wie granular bzw. komplex ein Service ist, kann individuell festgelegt werden. Ob der Service „Server” zum Beispiel auch das Betriebssystem und die Middleware einschließt oder ob statt eines einzelnen Servers eine Serverfarm betrachtet wird, ist aus Sicht der IT-Notfallvorsorge erst einmal unerheblich. Hauptsache ist, dass am Ende die Service-Liste alles abdeckt, worum sich die IT-Notfallvorsorge kümmern soll. Ein Kriterium hilft jedoch, zu prüfen, ob ein Service sinnvoll abgegrenzt ist. Es muss möglich sein, eine Person zu benennen, die für den Service in Gänze Verantwortung trägt. Solche Personen werden gerne Service Manager genannt.
Ein Service Manager muss nicht unbedingt der technische Experte für seinen Service sein, doch er trägt die Verantwortung, zum Beispiel für die Entscheidung, ob ein Notfallhandbuch benötigt wird, und in dem Fall, dass es so ist, auch dafür, dass das Notfallhandbuch vorhanden ist. Der Service Manager ist das Äquivalent zum Asset Owner im allgemeinen BCM. Wenn er kein IT-Experte ist, steht ihm für jedes IT Asset seines Services ein System Owner zur Verfügung, der über die notwendigen IT-Kenntnisse verfügt.
Grenzen der IT
Spannend ist bei der Erstellung des Servicekatalogs die Frage, wo die Grenzen der IT liegen. Sind zum Beispiel das Rechenzentrum oder die Stromversorgung noch Teil der IT und muss also die IT-Notfallvorsorge Pläne für deren Wiederaufbau pflegen? Und falls nicht: Wer tut es dann?
Spannend ist bei der Erstellung des Servicekatalogs die Frage, wo die Grenzen der IT liegen. Sind zum Beispiel das Rechenzentrum oder die Stromversorgung noch Teil der IT und muss also die IT-Notfallvorsorge Pläne für deren Wiederaufbau pflegen? Und falls nicht: Wer tut es dann?
BCM-Policy
Solche übergeordneten Klärungen werden im Regelfall in Policies vorgenommen, weswegen allgemeine BCM-Standards auch durchgängig fordern, dass es eine BCM-Policy geben muss. Allerdings können BCM-Themen auch in anderen Policies mit behandelt werden, etwa in der Information Security Policy.
Solche übergeordneten Klärungen werden im Regelfall in Policies vorgenommen, weswegen allgemeine BCM-Standards auch durchgängig fordern, dass es eine BCM-Policy geben muss. Allerdings können BCM-Themen auch in anderen Policies mit behandelt werden, etwa in der Information Security Policy.
5 Servicesteckbrief
Zweiter Schritt
Auch im zweiten Prozessschritt widmet sich der Prozess einer Aufgabe, die an sich gar nicht Kernthema der IT-Notfallvorsorge ist, sondern eine Grundaufgabe für jede IT-Organisation. Wenn der Titel eines IT Service bekannt ist, ist damit noch lange nicht klar, von was genau die Rede ist. Findet sich zum Beispiel in der Service-Liste die Angabe „E-Mail”, gibt es viele Möglichkeiten, was damit gemeint sein könnte und was demzufolge im zugehörigen Notfallhandbuch behandelt werden muss.
Auch im zweiten Prozessschritt widmet sich der Prozess einer Aufgabe, die an sich gar nicht Kernthema der IT-Notfallvorsorge ist, sondern eine Grundaufgabe für jede IT-Organisation. Wenn der Titel eines IT Service bekannt ist, ist damit noch lange nicht klar, von was genau die Rede ist. Findet sich zum Beispiel in der Service-Liste die Angabe „E-Mail”, gibt es viele Möglichkeiten, was damit gemeint sein könnte und was demzufolge im zugehörigen Notfallhandbuch behandelt werden muss.
| • | Geht es um die Applikation, und wenn ja, um welche Teile? Clients wie Thunderbird? Server-Software wie Microsoft Exchange? Apps für Smartphones und Tablets? |
| • | Geht es um die für den Betrieb der Applikationen nötigen Plattformen, zum Beispiel den Exchange-Server? Ist in diesem Fall die ganze Kette von der Hardware über die Virtualisierungsplattform und das Betriebssystem bis zur Middleware betroffen oder nur ein Teil davon? |
| • | Ist das Netz, physikalisch oder logisch, ganz oder beschränkt auf bestimmte Protokolle, inbegriffen? Was ist mit den Leistungen der Netzwerkbetreiber und ISPs? |
| • | Was ist mit unterstützenden Diensten, zum Beispiel Directories, Zertifikatsdiensten, SPAM-Filtern, Verschlüsselung usw.? |
| • | Geht es nur um den Austausch von Nachrichten oder auch um andere Funktionen, die die einschlägige Software heute fast durchgängig bietet, wie etwa Kalenderfunktionen, Termin- und Aufgabenmanagement? |
Die Liste solcher Fragen lässt sich beliebig erweitern, und alle Fragen müssen beantwortet werden. Wenn nicht eindeutig klar ist, welche Funktionen und Komponenten mit einem Servicenamen verbunden sind – im Englischen spricht man vom Scope – ist auch unbestimmt, was die Notfallvorsorge schützen soll.
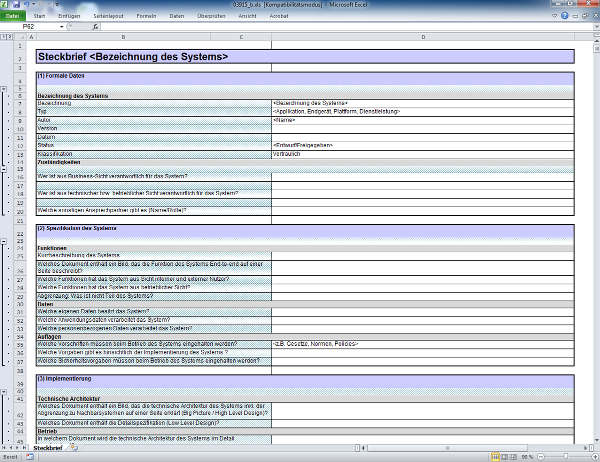
Steckbrief
Unter der Bezeichnung Servicesteckbrief wird vorgeschlagen, ein kurzes Dokument zu verfassen, das definiert, was zum diskutierten Service gehört und wo die Grenzen liegen. Wichtige Detailinformationen in einem Servicesteckbrief sind:
Unter der Bezeichnung Servicesteckbrief wird vorgeschlagen, ein kurzes Dokument zu verfassen, das definiert, was zum diskutierten Service gehört und wo die Grenzen liegen. Wichtige Detailinformationen in einem Servicesteckbrief sind:
| • | Die (wesentlichen) Funktionen, und zwar aus Sicht der Nutzer des Service |
| • | Die kritischen Ressourcen: Hardware, Software, Netzwerke und Daten |
| • | Die betriebliche Umgebung, zum Beispiel Gebäude und technische Infrastruktur und das Betriebspersonal |
| • | Abhängigkeiten von internen und externen Zulieferungen und Diensten, ohne die der Service nicht funktioniert |
| • | Rollen und Zuständigkeiten, zum Beispiel Ansprechpartner in Störfällen |
| • | Das aktuelle Verfügbarkeitskonzept, z. B. welche Redundanzen es gibt und wie das Backup von Daten aussieht |
| • | Zu guter Letzt: Die internen und externen Nutzer und die mit ihnen vereinbarten Serviceverfügbarkeiten |
Form
Der Steckbrief kann ein ausführliches Text-Dokument sein, aber manchmal reicht auch ein kurzes Summary, aus dem auf weiterführende Informationen verwiesen wird, zum Beispiel die eigentliche Systemdokumentation.
Der Steckbrief kann ein ausführliches Text-Dokument sein, aber manchmal reicht auch ein kurzes Summary, aus dem auf weiterführende Informationen verwiesen wird, zum Beispiel die eigentliche Systemdokumentation.
Der Steckbrief muss für alle Services eine einheitliche Form haben. Nur so lässt sich effizient prüfen, ob er den qualitativen Anforderungen der IT-Notfallvorsorge genügt, das heißt, ob alle nötigen Informationen vorhanden sind. Ein einfaches Beispiel ist als Arbeitshilfe im Excel-Format beigefügt. Diese kann nur eine grobe Orientierung geben und muss an die tatsächlichen Anforderungen im konkreten Fall angepasst werden. Größere Organisationen verfügen häufig über eine Configuration Management Database (CMDB), in die ein solcher Steckbrief integriert werden kann.[ 01720_b.xlsx]
01720_b.xlsx]Big Picture
Es ist äußerst hilfreich, die Architektur des Service in einer Grafik zu visualisieren, und zwar „end-to-end”. Dieses Bild muss auf eine Seite passen. Solche Übersichten werden Big Picture genannt. Sie sind eine wichtige Anlage zum Steckbrief.
Es ist äußerst hilfreich, die Architektur des Service in einer Grafik zu visualisieren, und zwar „end-to-end”. Dieses Bild muss auf eine Seite passen. Solche Übersichten werden Big Picture genannt. Sie sind eine wichtige Anlage zum Steckbrief.
Daten im Notfall-Monitor
Bezüglich des Status der Servicedokumentation werden für das Controlling der IT-Notfallvorsorge je Service die in Tabelle 2 aufgeführten Angaben benötigt.
Bezüglich des Status der Servicedokumentation werden für das Controlling der IT-Notfallvorsorge je Service die in Tabelle 2 aufgeführten Angaben benötigt.
Tabelle 2: Elemente des Servicekatalogs
Spalte | Information | Beschreibung |
|---|---|---|
2A | Datum des Servicesteckbriefs | Wann wurde der Steckbrief erstellt bzw. letztmals aktualisiert? Falls diese Angabe fehlt, bedeutet das, dass es keinen Steckbrief gibt. |
2B | Qualität | Wie bewertet der Notfallbeauftragte die Aktualität und Qualität des Inhalts des Steckbriefs? |
Qualität/Erläuterung | Erläuterung der Angabe zur Qualität |
6 Fakten, Bewertungen und Maßnahmen
Fakten
Der Notfallbeauftragte muss einige Fakten sammeln und auswerten, wie etwa das Datum der letzten Revision eines Steckbriefs. Dafür steht beispielhaft Spalte 2A der Tabelle im vorigen Kapitel. Was genau heißt es aber, dass die Servicebeschreibung zu lange nicht mehr überprüft und verbessert wurde, und was folgt daraus? Das ist eine Bewertung, wie sie etwa in die Angabe in Spalte 2B einfließt. Neben der Feststellung von Tatsachen, zum Beispiel, ob es eine Servicebeschreibung gibt, geht es auch darum, sich ein Bild von der Qualität dessen zu machen, was unter der Überschrift IT-Notfallvorsorge produziert wurde. Es kommt nicht darauf an, ob es ein Dokument mit dem Titel „Notfallhandbuch für den Service E-Mail” gibt und wie dick das ist. Was bekannt sein muss, ist, ob dieses Dokument etwas taugt, und zwar in dem Sinn, ob es hilft, Versprechen zur Serviceverfügbarkeit einzuhalten, die den Kunden der IT gegeben wurden.
Der Notfallbeauftragte muss einige Fakten sammeln und auswerten, wie etwa das Datum der letzten Revision eines Steckbriefs. Dafür steht beispielhaft Spalte 2A der Tabelle im vorigen Kapitel. Was genau heißt es aber, dass die Servicebeschreibung zu lange nicht mehr überprüft und verbessert wurde, und was folgt daraus? Das ist eine Bewertung, wie sie etwa in die Angabe in Spalte 2B einfließt. Neben der Feststellung von Tatsachen, zum Beispiel, ob es eine Servicebeschreibung gibt, geht es auch darum, sich ein Bild von der Qualität dessen zu machen, was unter der Überschrift IT-Notfallvorsorge produziert wurde. Es kommt nicht darauf an, ob es ein Dokument mit dem Titel „Notfallhandbuch für den Service E-Mail” gibt und wie dick das ist. Was bekannt sein muss, ist, ob dieses Dokument etwas taugt, und zwar in dem Sinn, ob es hilft, Versprechen zur Serviceverfügbarkeit einzuhalten, die den Kunden der IT gegeben wurden.
Bewertung
Wertende Aussagen spiegeln stets die subjektive Meinung eines Betrachters wider. Es ist weder falsch noch bedenklich, wenn verschiedene Personen in Anbetracht bestimmter Fakten zu unterschiedlichen Bewertungen kommen. Angenommen, dass ermittelt wurde, dass der letzte Review des Steckbriefs eines Service vor 18 Monaten erfolgte, wie sollte dieses Faktum bewertet werden? Der eine mag denken, dass Reviews im Abstand von zwei Jahren absolut in Ordnung sind, vielleicht, weil er weiß, dass wegen der dünnen Personaldecke bereits das ein Erfolg wäre. Für jemand anderen ist der gleiche Umstand gänzlich inakzeptabel, denn schon innerhalb eines deutlich kürzeren Zeitraums ändern sich technische Architekturen oft radikal. Wichtig ist am Ende zweierlei:
Wertende Aussagen spiegeln stets die subjektive Meinung eines Betrachters wider. Es ist weder falsch noch bedenklich, wenn verschiedene Personen in Anbetracht bestimmter Fakten zu unterschiedlichen Bewertungen kommen. Angenommen, dass ermittelt wurde, dass der letzte Review des Steckbriefs eines Service vor 18 Monaten erfolgte, wie sollte dieses Faktum bewertet werden? Der eine mag denken, dass Reviews im Abstand von zwei Jahren absolut in Ordnung sind, vielleicht, weil er weiß, dass wegen der dünnen Personaldecke bereits das ein Erfolg wäre. Für jemand anderen ist der gleiche Umstand gänzlich inakzeptabel, denn schon innerhalb eines deutlich kürzeren Zeitraums ändern sich technische Architekturen oft radikal. Wichtig ist am Ende zweierlei:
| Wichtig | |
| • | Eine Bewertung muss durch diejenige Person erfolgen, die die Verantwortung für die Konsequenzen der Bewertung trägt. Im Fall des Controllings der IT-Notfallvorsorge ist das der Notfallbeauftragte. |
| • | Die Bewertung darf nicht willkürlich erfolgen. Sie muss vielmehr nachvollziehbar sein. Dies wird erreicht, indem eine Bewertung einer wohldefinierten Methode folgt und dabei klare Metriken, also Maßstäbe einer Bewertung, anwendet. |
Metriken
Eine Metrik zeichnet sich durch folgende Eigenschaften aus:
Eine Metrik zeichnet sich durch folgende Eigenschaften aus:
| • | Zur Beschreibung einer Eigenschaft des Service wird nur eine feste und zudem sehr begrenzte Anzahl von Werten zugelassen. Freitexte sind nur für eine Begründung bzw. Erklärung der getroffenen Wahl zulässig. Beispiel: Für die Qualität des Steckbriefs sind nur die Werte „Gut”, „Zufriedenstellend”, „Mangelhaft” und „Ungenügend” erlaubt. |
| • | Ein Regelwerk legt fest, wann welcher der zulässigen Werte zu verwenden ist. Beispiel: Der Wert „Mangelhaft” ist unter anderem dann zu wählen, wenn kein Big Picture vorhanden ist oder der letzte Review mehr als zwei Jahre zurückliegt. |
Starre Metriken haben den Nachteil, dass nur selten einer der angebotenen Werte exakt passt. Darum ist es hilfreich, zu den bewertenden Aussagen Kommentare zu erfassen, um zu erläutern, warum die Bewertung so erfolgte. Siehe als Beispiel auch dazu Tabelle 2, Spalte 2B im letzten Abschnitt.
Metriken in der BCM-Policy
Die bei der IT-Notfallvorsorge genutzten Metriken sollten in der allgemeinen BCM-Policy formuliert werden. Dann können Sie auch für andere BCM-Szenarien genutzt werden, etwa dem Ausfall des Personals oder eines Dienstleisters.
Die bei der IT-Notfallvorsorge genutzten Metriken sollten in der allgemeinen BCM-Policy formuliert werden. Dann können Sie auch für andere BCM-Szenarien genutzt werden, etwa dem Ausfall des Personals oder eines Dienstleisters.
Der Prozess der IT-Notfallvorsorge muss definieren, was aus einem bestimmten Fakt oder aus einer Bewertung folgt.
| Maßnahmen | |
| • | Es ist festzulegen, welche Maßnahmen aus einer bestimmten Bewertung abzuleiten sind.Beispiel: Wenn die Qualität des Steckbriefs nicht mindestens „Zufriedenstellend” ist, muss binnen eines Monats ein Review durch den Service-Verantwortlichen durchgeführt werden. |
| • | Es ist festzulegen, welche Konsequenzen eine bestimmte Aussage für den weiteren Prozess hat.Beispiel: Wenn die Qualität des Steckbriefs nicht mindestens „Zufriedenstellend” ist, sind alle anderen Dokumente der IT-Notfallvorsorge für diesen Service wertlos. Es ist egal, ob es für ihn eine Business-Impact-Analyse, eine Risikoanalyse, ein Notfallhandbuch oder was sonst auch immer gibt oder nicht. Die Informationen in diesen Dokumenten können nicht verlässlich sein und sollten nur mit großer Vorsicht benutzt, besser aber ganz ignoriert werden. |
Transparenz
Metriken liefern die Voraussetzung dafür, dass ein konsequentes Controlling sehr klare Aussagen über den Zustand der Notfallvorsorge treffen kann. Beispiele für Metriken sind:
Metriken liefern die Voraussetzung dafür, dass ein konsequentes Controlling sehr klare Aussagen über den Zustand der Notfallvorsorge treffen kann. Beispiele für Metriken sind:
| • | „Für sieben von elf Services lohnt sich ein Notfallhandbuch nicht, weil sie nicht hinreichend kritisch sind.” |
| • | „Für 95 % aller kritischen IT Services gibt es de facto keine IT-Notfallvorsorge.” |
| • | „Bei 80 % dieser Services liegt es daran, dass es keine hinreichende Servicebeschreibung gibt.” |
Solche Erkenntnisse werden ohne jede Beschönigung präsentiert, und weil das auf der Grundlage objektiver Fakten und nachvollziehbarer Bewertungen geschieht, sind sie auch nicht angreifbar.
Es wird häufig übersehen, dass die erste und vielleicht auch wichtigste Aufgabe der IT-Notfallvorsorge darin besteht, Transparenz zu schaffen. Das passiert nun ziemlich radikal. Nicht jedem wird das gefallen.
7 Business Impact Analysis
Mögliche kritische Schäden erkennen
IT-Notfallvorsorge ist ein aufwändiges und teures Unterfangen, das sich für einen einzelnen Service nur lohnt, wenn dieser hinreichend wichtig ist. Es gilt deshalb, für alle Services des Servicekatalogs herauszufinden, ob sie hinreichend wichtig sind. Aus dem Blickwinkel der IT-Notfallvorsorge ist das dann der Fall, wenn ein Serviceausfall einen kritischen Schaden verursachen könnte. Ob das der Fall ist, ermittelt ein Vorgang, der Business Impact Analysis oder kurz BIA genannt wird.
IT-Notfallvorsorge ist ein aufwändiges und teures Unterfangen, das sich für einen einzelnen Service nur lohnt, wenn dieser hinreichend wichtig ist. Es gilt deshalb, für alle Services des Servicekatalogs herauszufinden, ob sie hinreichend wichtig sind. Aus dem Blickwinkel der IT-Notfallvorsorge ist das dann der Fall, wenn ein Serviceausfall einen kritischen Schaden verursachen könnte. Ob das der Fall ist, ermittelt ein Vorgang, der Business Impact Analysis oder kurz BIA genannt wird.
Drei wesentliche Fragen
Beschränkt auf die Anforderungen der IT-Notfallvorsorge ist eine BIA unkompliziert. Sie stellt zu jedem IT Service drei Fragen in den Vordergrund:
Beschränkt auf die Anforderungen der IT-Notfallvorsorge ist eine BIA unkompliziert. Sie stellt zu jedem IT Service drei Fragen in den Vordergrund:
| • | Welche Geschäftsprozesse wären gar nicht oder nur noch stark eingeschränkt durchführbar, wenn der betrachtete IT Service nicht mehr ordnungsgemäß funktioniert? |
| • | Welche Bedeutung haben diese Geschäftsprozesse für das Unternehmen? Könnte ein Schaden entstehen, der den Erfolg des Unternehmens nachhaltig beeinträchtigt oder sogar existenzbedrohend ist, wenn sie nicht mehr wie gewohnt durch die IT unterstützt werden? |
| • | Ab welcher Ausfallzeit würde es zu einem solchen Schaden kommen? |
Recovery Time Objective
Mit der Antwort auf die letzte Frage ist der wichtigste Parameter für die IT-Notfallvorsorge ermittelt: die maximal tolerierbare Ausfallzeit eines IT Service. Dieser Parameter wird üblicherweise Recovery Time Objective, kurz RTO, genannt.
Mit der Antwort auf die letzte Frage ist der wichtigste Parameter für die IT-Notfallvorsorge ermittelt: die maximal tolerierbare Ausfallzeit eines IT Service. Dieser Parameter wird üblicherweise Recovery Time Objective, kurz RTO, genannt.
Recovery Point Objective
Ein zweiter Parameter, der bekannt sein muss, ist die maximal tolerierbare Zeitdauer eines Datenverlusts. Sie wird Recovery Point Objective, kurz RPO, genannt.
Ein zweiter Parameter, der bekannt sein muss, ist die maximal tolerierbare Zeitdauer eines Datenverlusts. Sie wird Recovery Point Objective, kurz RPO, genannt.
Metrik der BIA
Die BIA der IT-Notfallvorsorge konzentriert sich auf ganz wenige Fragen. Sie betrachtet nur bestimmte Schadensereignisse. Das macht es vergleichsweise einfach, sie durchzuführen. An sich ist eine BIA, etwa für das Corporate Risk Management, sehr viel komplexer.
Die BIA der IT-Notfallvorsorge konzentriert sich auf ganz wenige Fragen. Sie betrachtet nur bestimmte Schadensereignisse. Das macht es vergleichsweise einfach, sie durchzuführen. An sich ist eine BIA, etwa für das Corporate Risk Management, sehr viel komplexer.
Für die Durchführung einer BIA wird eine Methodik benötigt. Sie muss vor allem folgende Fragen klären:
| Schaden | |
| • | Was ist ein Schaden?Beispiele für Schadensarten: Umsatzausfälle, Verstöße gegen Gesetze, Reputationsverlust, Nichteinhaltung von Verträgen. Die betrachteten Schäden sind identisch zu denen in andere BCM-Szenarien. |
| Schadensausmaß | |
| • | Wie kann beschrieben werden, wie hoch ein Schaden ist?Viele BIAs schlagen vor, das Schadensausmaß (impact) in Euro auszudrücken. Davon wird abgeraten. Abgesehen davon, dass der Versuch, einen Schaden finanziell zu bewerten, meist auf wildes Schätzen hinausläuft, nutzt diese Zahl auch nicht besonders. Es reicht schon eine grobe Einstufung über Begriffe wie „gering”, „durchschnittlich” oder „kritisch” aus, und zwar deshalb, weil sich die IT-Notfallvorsorge per Definition genau um die kritischen Services kümmern soll, und ein Service ist genau dann kritisch, wenn er kritische Schäden anrichten könnte. Die Kategorien der Schadenshöhe sind wieder identisch zu denen in anderen BCM-Szenarien. |
| Kriterien Kritikalität | |
| • | Wie wird gemessen, ob ein Schaden „kritisch” ist oder nicht?Dafür müssen für alle Schadensarten eigene Kriterien aufgestellt werden. Beispiel: Ein Schaden der Art „Gesetzesverstoß” ist „kritisch”, wenn es strafrechtliche Konsequenzen für die Beteiligten, zum Beispiel die Geschäftsführung, geben könnte. Als „hoch” wird er bei möglichen zivilrechtlichen Folgen bezeichnet und als „gering” sonst. |
Daten im Notfall-Monitor
Wenn in einem Unternehmen BIAs durchgeführt werden, ist das gewöhnlich ein wesentlich komplexerer Vorgang als hier beschrieben, doch das ist für die IT-Notfallvorsorge uninteressant. Ganz im Sinn der eingangs propagierten Pragmatik sind am Ende nur wenige Aussagen einer BIA wichtig, und zwar die in Tabelle 3 dargestellten.
Wenn in einem Unternehmen BIAs durchgeführt werden, ist das gewöhnlich ein wesentlich komplexerer Vorgang als hier beschrieben, doch das ist für die IT-Notfallvorsorge uninteressant. Ganz im Sinn der eingangs propagierten Pragmatik sind am Ende nur wenige Aussagen einer BIA wichtig, und zwar die in Tabelle 3 dargestellten.
Tabelle 3: Elemente des Servicekatalogs
Spalte | Information | Beschreibung |
|---|---|---|
3A | Datum der BIA | Wann wurde die letzte BIA durchgeführt?
Auch hier gilt: Ist das zu lange her, sind die Ergebnisse nicht verwertbar. |
3B | Kritikalität | Ergebnis der BIA: Wie kritisch ist der Service? Hierfür wird über alle Schadensarten hinweg der größtmögliche Schaden betrachtet. |
3C | RTO | Maximal tolerierbare Ausfallzeit |
3D | RPO | Maximal zulässige Zeit für Datenverlust |
3E | Priorisierung | Diese Angabe dient einer Priorisierung der kritischen Services untereinander. |
Vereinfachte BIA
In bestimmten Fällen kann auf eine BIA sogar verzichtet werden, weil das Ergebnis mit hoher Wahrscheinlichkeit auch so bekannt ist. Dabei spielt der Servicetyp eine wichtige Rolle (siehe Abschnitt 4 Servicekatalog). Die Methodik der BIA kann dazu Regeln wie die folgenden vorsehen:
In bestimmten Fällen kann auf eine BIA sogar verzichtet werden, weil das Ergebnis mit hoher Wahrscheinlichkeit auch so bekannt ist. Dabei spielt der Servicetyp eine wichtige Rolle (siehe Abschnitt 4 Servicekatalog). Die Methodik der BIA kann dazu Regeln wie die folgenden vorsehen:
| • | Ist ein Service vom Typ „Plattform”, ist er per Definition kritisch. |
| • | Ist ein Service vom Typ „Endgeräte”, ist er nicht kritisch. |
8 Risikoanalyse
Durch die bisherigen Arbeiten ist bekannt, welche IT Services es gibt und welche davon so kritisch sind, dass sich die IT-Notfallvorsorge um sie kümmern muss. Für alle anderen ist der Prozess hier schon zu Ende. Für sie lohnt sich ein Notfallhandbuch nicht. Falls sich der Service Manager trotzdem die Zeit nehmen will, eine IT-Notfallvorsorge zu betreiben, so ist das seine eigene Entscheidung. Es stellt sich allerdings die Frage, ob die damit verbundenen Aufwände nicht einfach Verschwendung von Zeit und Geld sind.
Für die kritischen Services ist IT-Notfallvorsorge obligatorisch. Das Einzige, was eventuell noch zu klären ist, und zwar wegen der vermutlich begrenzten Mittel für die nun anstehenden Arbeiten, ist die Reihenfolge, in der diese Services behandelt werden. Dafür ist eine Priorisierung innerhalb der Gruppe der kritischen Services unvermeidlich. Siehe dazu Spalte 3C der Tabelle 3 im vorherigen Abschnitt.
Szenarien
Das wichtigste Ergebnis der IT-Notfallvorsorge für einen IT Service wird das Notfallhandbuch sein. Darin wird die Strategie beschrieben, mittels deren erreicht werden soll, dass bei einem Serviceausfall einerseits unvermeidliche Schäden begrenzt werden können und andererseits die Leistungen, die die Kunden benötigen, möglichst rasch wieder angeboten werden können.
Das wichtigste Ergebnis der IT-Notfallvorsorge für einen IT Service wird das Notfallhandbuch sein. Darin wird die Strategie beschrieben, mittels deren erreicht werden soll, dass bei einem Serviceausfall einerseits unvermeidliche Schäden begrenzt werden können und andererseits die Leistungen, die die Kunden benötigen, möglichst rasch wieder angeboten werden können.
Genau genommen gibt es nicht nur einen Plan für den Notfall, sondern zahlreiche, und zwar für jedes denkbare Schadensbild einen. Diese Schadensbilder sind zu unterschiedlich, als dass es möglich wäre, sie alle mit einem einzigen Plan in den Griff bekommen zu wollen. Die Maßnahmen, die zum Beispiel beim Verlust von Hardware zu ergreifen sind, sind ganz andere als die, die sinnvoll sind, falls ein Hacker eine Datenbank löscht oder falls das Personal streikt. Ein bestimmtes Schadensbild wird meist als Szenario bezeichnet. Für jedes Szenario, bei dem ein kritischer Schaden droht, muss ein passender Plan entworfen werden.
Schadensbilder identifizieren
Der nächste Prozessschritt der IT-Notfallvorsorge leitet sich unmittelbar aus folgender Frage ab: Welches sind die oben so beiläufig erwähnten „denkbaren Schadensbilder bzw. Störfallszenarien”? Sie zu identifizieren und in ihrer Wahrscheinlichkeit abzuschätzen ist Aufgabe einer Risikoanalyse.
Der nächste Prozessschritt der IT-Notfallvorsorge leitet sich unmittelbar aus folgender Frage ab: Welches sind die oben so beiläufig erwähnten „denkbaren Schadensbilder bzw. Störfallszenarien”? Sie zu identifizieren und in ihrer Wahrscheinlichkeit abzuschätzen ist Aufgabe einer Risikoanalyse.
Metrik der Risikoanalyse
Wie die BIA ist auch die Risikoanalyse grundsätzlich eine komplexe und schwierige Arbeit, und wie bei der BIA kann die IT-Notfallvorsorge sie sehr einfach halten, indem sie sich auf folgende Fragen konzentriert:
Wie die BIA ist auch die Risikoanalyse grundsätzlich eine komplexe und schwierige Arbeit, und wie bei der BIA kann die IT-Notfallvorsorge sie sehr einfach halten, indem sie sich auf folgende Fragen konzentriert:
| • | Wie können sich Serviceausfälle darstellen, d. h., wie sehen die charakteristischen Schadensbilder aus? Die IT-Notfallvorsorge profitiert erheblich davon, dass sie sich nicht mit der Frage beschäftigen muss, wie oder warum es zu einem Schaden gekommen sein könnte. Es interessiert nur das Resultat. Beispiel: Szenario „Verlust des Servers”. Es ist egal, ob die Server-Hardware nicht mehr vorhanden ist, weil das Rechenzentrum abgebrannt ist, ein Administrator mit der Axt gewütet hat oder das System einfach kaputtgegangen ist. In allen Fällen lautet die Aufgabe: Der Server muss wieder aufgebaut werden. |
| • | Welche Annahmen werden hinsichtlich des Szenarios getroffen? Beispiel: Szenario „Verlust der Datenbank”, Annahme „Integres Backup der Datenbank ist verfügbar”. Oder auch nicht. |
| • | Bei welchen dieser ermittelten Szenarien könnte es zu einem kritischen Schaden kommen? Um diese Frage zu beantworten, reicht es, zu klären, ob die Gefahr besteht, dass bei Eintritt des Szenarios der Wiederanlauf nicht innerhalb der RTO-Zeit aus der BIA garantiert werden kann oder dass der Datenverlust größer RPO ist. |
Qualität der Risikoanalyse
Es ist keine triviale Aufgabe, bei einer Betrachtung eines IT Service, etwa seiner technischen Struktur, mögliche Ausfallszenarien zu erkennen. Wenn es um IT-Notfallvorsorge geht, denken viele zunächst – und manchmal auch nur – an Ereignisse, die eine physische Zerstörung von Hardware zur Folge haben, wie der Ausfall eines Rechenzentrums nach einem Brand. Es ist extrem wichtig, sehr viel breiter zu denken. Der Verlust von Daten ist in der Regel dramatischer als der Verlust von Systemen oder Räumlichkeiten, und die Folgen eines vorsätzlichen Angriffs von Insidern sind nachhaltiger als die von Unfällen. Völlig übersehen werden häufig externe Einflüsse wie der Ausfall von Dienstleistern. Gerade mit Risikoanalysen müssen Fachleute beauftragt werden, die in diesem Metier eine gewisse Erfahrung mitbringen. Andernfalls kann es schnell passieren, dass nur die offensichtlichen, aber nicht unbedingt die kritischen Szenarien betrachtet werden.
Es ist keine triviale Aufgabe, bei einer Betrachtung eines IT Service, etwa seiner technischen Struktur, mögliche Ausfallszenarien zu erkennen. Wenn es um IT-Notfallvorsorge geht, denken viele zunächst – und manchmal auch nur – an Ereignisse, die eine physische Zerstörung von Hardware zur Folge haben, wie der Ausfall eines Rechenzentrums nach einem Brand. Es ist extrem wichtig, sehr viel breiter zu denken. Der Verlust von Daten ist in der Regel dramatischer als der Verlust von Systemen oder Räumlichkeiten, und die Folgen eines vorsätzlichen Angriffs von Insidern sind nachhaltiger als die von Unfällen. Völlig übersehen werden häufig externe Einflüsse wie der Ausfall von Dienstleistern. Gerade mit Risikoanalysen müssen Fachleute beauftragt werden, die in diesem Metier eine gewisse Erfahrung mitbringen. Andernfalls kann es schnell passieren, dass nur die offensichtlichen, aber nicht unbedingt die kritischen Szenarien betrachtet werden.
Das Ergebnis der Risikoanalyse stellt sich im Notfall-Monitor wie in Tabelle 4 gezeigt dar.
Tabelle 4: Ergebnis der Risikoanalyse
Spalte | Information | Beschreibung |
|---|---|---|
4A | Datum der Risikoanalyse | Wann wurde die letzte Risikoanalyse durchgeführt?
Auch hier gilt: Ist das zu lange her, sind die Ergebnisse nicht verwertbar. |
4B | Szenario | Beschreibung eines Szenarios inkl. getroffener Annahmen |
4C | Risiko | Ergebnis der Risikoanalyse: Wie wahrscheinlich ist es, dass ein Notfall eintritt, bei dem die geforderten RTO und/oder RPO nicht eingehalten werden können? |
4D | Notfallhandbuch | Entscheid zum Ausfallrisiko: Wird für dieses Szenario ein Notfallhandbuch benötigt? |
Spalte 4D fasst das Ergebnis aller analytischen Tätigkeiten in einem Wort zusammen. Die bisherigen Überlegungen dienten nur dem Zweck, diese zentrale Entscheidung abzusichern. Lautet sie „nein”, sind alle weiteren Schritte des Notfallvorsorgeprozesses für das Szenario nicht mehr relevant.
Da es zu jedem IT Service beliebig viele Schadensszenarien geben kann, kommen die Werte 4B bis 4D im Notfall-Monitor mehrfach vor. Ein Beispiel zeigt der Auszug in Tabelle 5.
Tabelle 5: Mehrere Szenarien pro IT Service möglich
1Service | 2Steckbrief | 3BIA | 4Risikoanalyse | ... | |
|---|---|---|---|---|---|
RTO | Szenario | Notfall-handbuch | |||
E-Mail | ... | 1 Tag | Ausfall Exchange Server | ja | ... |
Ausfall Client | nein | n/a | |||
... | |||||
Die Tabelle 5 deutet bereits an, dass alle in den noch folgenden Prozessschritten ermittelten Fakten und vorgenommenen Bewertungen für jedes Szenario, für das ein Notfallhandbuch vorgesehen ist, separat zu dokumentieren sind.
9 Notfallhandbuch
Auch zu Beginn dieses Abschnitts zunächst ein Rückblick: Was ist der Erkenntnisstand an dieser Stelle im Prozess?
Es ist bekannt, welche Notfallhandbücher nötig sind, nämlich jeweils
| • | für ein ganz bestimmtes Schadensbild (Szenario) |
| • | eines ganz bestimmten IT Service, weil |
| • | in diesem Szenario Ausfallzeiten drohen, die länger sind als die Zeit, in der wichtige Geschäftsprozesse auf den IT Service verzichten können, ohne dass es zu einem kritischen Schaden für das Unternehmen kommt. |
Notfallhandbuch
Es muss nun ein Plan entworfen werden, der erklärt, wie ein Wiederanlauf des Service in hinreichend kurzer Zeit erreicht werden kann. Das Notfallhandbuch ist das Dokument, in dem dieser Plan beschrieben wird. In diesem Beitrag kann nicht im Detail darauf eingegangen werden, wie ein Notfallhandbuch aussieht. Es soll nur daran erinnert werden, dass ein Plan für den Notfall auf jeden Fall zwei Aspekte abdecken muss: den Continuity Plan für den Service und die Recovery Plans für die Ressourcen, die der Service nutzt.
Es muss nun ein Plan entworfen werden, der erklärt, wie ein Wiederanlauf des Service in hinreichend kurzer Zeit erreicht werden kann. Das Notfallhandbuch ist das Dokument, in dem dieser Plan beschrieben wird. In diesem Beitrag kann nicht im Detail darauf eingegangen werden, wie ein Notfallhandbuch aussieht. Es soll nur daran erinnert werden, dass ein Plan für den Notfall auf jeden Fall zwei Aspekte abdecken muss: den Continuity Plan für den Service und die Recovery Plans für die Ressourcen, die der Service nutzt.
Continuity Plan
Nach einem Ausfall der IT muss das Augenmerk der IT-Notfallvorsorge zunächst auf dem Kunden liegen. Es müssen Sofortmaßnahmen eingeleitet werden, um Schäden zu begrenzen. Dann aber müssen den Kunden der IT Provisorien angeboten werden, die sie in die Lage versetzen, die wichtigsten Arbeiten erledigen zu können, solange die regulären IT Services nicht verfügbar sind. Das Kapitel des Notfallhandbuchs, in dem entsprechende Strategien beschrieben werden, ist der Continuity Plan.
Nach einem Ausfall der IT muss das Augenmerk der IT-Notfallvorsorge zunächst auf dem Kunden liegen. Es müssen Sofortmaßnahmen eingeleitet werden, um Schäden zu begrenzen. Dann aber müssen den Kunden der IT Provisorien angeboten werden, die sie in die Lage versetzen, die wichtigsten Arbeiten erledigen zu können, solange die regulären IT Services nicht verfügbar sind. Das Kapitel des Notfallhandbuchs, in dem entsprechende Strategien beschrieben werden, ist der Continuity Plan.
Recovery Plan
Es muss für alle Ressourcen, die ein Service nutzt, zum Beispiel die einzelnen Systeme und Applikationen, eine Strategie geben, wie sie bei einem Komplettausfall bzw. Verlust wiederhergestellt werden können. Die Dokumentation dazu heißt Wiederanlaufplan bzw. Recovery Plan.
Es muss für alle Ressourcen, die ein Service nutzt, zum Beispiel die einzelnen Systeme und Applikationen, eine Strategie geben, wie sie bei einem Komplettausfall bzw. Verlust wiederhergestellt werden können. Die Dokumentation dazu heißt Wiederanlaufplan bzw. Recovery Plan.
Das Controlling der IT-Notfallvorsorge stellt sicher, dass genau diese Dokumente bzw. Teile des Notfallhandbuchs existieren, und zwar nicht nur dem Namen nach, sondern als praxistaugliches Arbeitsdokument für den Notfall.
Daten im Notfall-Monitor
Die Tabelle 6 listet die Daten auf, die zum Notfallhandbuch im Notfall-Monitor geführt werden müssen.
Die Tabelle 6 listet die Daten auf, die zum Notfallhandbuch im Notfall-Monitor geführt werden müssen.
Tabelle 6: Daten zum Notfallhandbuch im Notfall-Monitor
Spalte | Information | Beschreibung |
|---|---|---|
5A | Datum des Notfallhandbuchs | Wann wurde der letzte Review durchgeführt?
Auch hier gilt: Ist das zu lange her, sind die Ergebnisse nicht verwertbar. |
5B | Güte des Inhalts | Wie gut ist der dokumentierte Plan? (Siehe im Folgenden) |
5C | Einhaltung der Vorgaben | Können mit diesem Plan die Vorgaben der Kunden (maximale Ausfallzeit RTO und maximale Datenverlustrate RPO) eingehalten werden? |
5D | Verlässlichkeit | Wie sicher ist, dass der dargelegte Plan funktionieren wird? |
Qualitätssicherung
Die Spalte 5B ist möglicherweise der Dreh- und Angelpunkt des gesamten Controllings der IT-Notfallvorsorge. Hier soll der Notfallbeauftragte bewerten, was er von dem Plan hält, der in dem ihm vorgelegten Notfallhandbuch dokumentiert ist.
Die Spalte 5B ist möglicherweise der Dreh- und Angelpunkt des gesamten Controllings der IT-Notfallvorsorge. Hier soll der Notfallbeauftragte bewerten, was er von dem Plan hält, der in dem ihm vorgelegten Notfallhandbuch dokumentiert ist.
| • | Ist er vollständig? |
| • | Ist er ausreichend detailliert, so dass die erforderlichen Arbeiten auch von einer Vertretung (z. B. des zuständigen Administrators) durchgeführt werden können? |
| • | Macht er den Eindruck, ob er durchdacht ist und funktionieren könnte? |
Führt die Bewertung zu einem negativen Ergebnis, wird das Controlling den Fall so behandeln, als ob es gar kein Notfallhandbuch gäbe. Auch wenn das hart erscheinen mag: Angesichts dessen, was eventuell davon abhängt, ob ein Notfallhandbuch brauchbar ist, sind Gefälligkeitsaussagen an dieser Stelle fehl am Platz.
Templates
Ob ein Notfallhandbuch vollständig ist, lässt sich nur feststellen, wenn zuvor definiert wurde, was es enthalten muss. Darum müssen für Continuity Plans und Recovery Plans Vorlagen (Templates) entworfen werden, deren Verwendung vorgeschrieben wird.
Ob ein Notfallhandbuch vollständig ist, lässt sich nur feststellen, wenn zuvor definiert wurde, was es enthalten muss. Darum müssen für Continuity Plans und Recovery Plans Vorlagen (Templates) entworfen werden, deren Verwendung vorgeschrieben wird.
10 Notfallübungen
Verlässlichkeit testen
Die im vorigen Abschnitt aufgeworfene Frage nach der Verlässlichkeit eines Plans für den Notfall (Spalte 5D) lässt sich am besten beantworten, indem der Plan im Rahmen einer Notfallübung getestet wird.
Die im vorigen Abschnitt aufgeworfene Frage nach der Verlässlichkeit eines Plans für den Notfall (Spalte 5D) lässt sich am besten beantworten, indem der Plan im Rahmen einer Notfallübung getestet wird.
Grundvoraussetzung für einen Test, der verwertbare Aussagen liefert, ist, dass nicht irgendetwas getestet wird. Hier ist eine gesunde Skepsis gegenüber den Systemspezialisten angebracht. Diese neigen nämlich dazu, bevorzugt das zu testen, was sie eh einigermaßen im Griff haben.
Mit der bisher vorgeschlagenen Vorgehensweise ist allerdings klar, was Testgegenstand sein muss, nämlich das Vorgehen in einem der in der Risikoanalyse identifizierten Ausfallszenarien anhand des dafür dokumentierten Plans, und nichts anderes. Lautet das Szenario zum Beispiel „Ausfall der Datenbank” und wurde dabei die Annahme gemacht, dass der Datenbankserver inklusive Betriebssystem noch zur Verfügung steht, so muss der Test wenigstens die Schritte „Einrichten der Datenbank” und „Rückspielen der Daten aus dem Backup” umfassen. Das Aufsetzen des Servers selbst ist hingegen hier irrelevant. Es ist gegebenenfalls Teil der Übungen zum Notfallhandbuch für die Serverfarm.
Daten im Notfall-Monitor
Die Tabelle 7 listet die Daten auf, die der Notfallbeauftragte zu den Notfallübungen wissen möchte und die entsprechend im Notfall-Monitor geführt werden.
Die Tabelle 7 listet die Daten auf, die der Notfallbeauftragte zu den Notfallübungen wissen möchte und die entsprechend im Notfall-Monitor geführt werden.
Tabelle 7: Daten zu Notfallübungen im Notfall-Monitor
Spalte | Information | Beschreibung |
|---|---|---|
6A | Testplan | Welche Art von Test ist vorgesehen? |
6B | Datum des letzten Tests | Auch für Tests gilt: Liegen sie zu lange zurück, ist ihre Aussagekraft begrenzt. |
6C | Ergebnis | Wie erfolgreich war der Test? |
6D | Nächster Test | Für wann ist der nächste Test vorgesehen? |
Testplan
Test ist nicht gleich Test. Es gibt die unterschiedlichsten Möglichkeiten, Pläne zu verifizieren. Spannend ist vor allem die Frage, wie viel praktisch getestet werden kann und wie viel davon in einer realen Umgebung, also unter Produktionsbedingungen. Jede Art von Test wird für ein bestimmtes Maß an Gewissheit sorgen. Es ist notwendig, für jedes betrachtete Schadensszenario zu bestimmen, welche Art von Test hilft, das jeweils nötige Maß an Gewissheit zu erreichen. Nicht in jedem Fall ist ein praktischer Test in der produktiven Umgebung zwingend nötig. Manchmal reicht ein Test in einer Testumgebung, manchmal ein simulierter Test am Schreibtisch („Table-Top-Übung”), manchmal ein Review des Notfallhandbuchs durch einen unabhängigen Fachmann. Die aus Sicht der Beteiligten, Systemspezialisten wie Notfallbeauftragter, angemessene Strategie soll als Testplan beschrieben werden, und zwar unabhängig von der Frage, ob ein solcher Test durchführbar ist. In Spalte 6A wird überwacht, ob es einen aktuellen Testplan gibt.
Test ist nicht gleich Test. Es gibt die unterschiedlichsten Möglichkeiten, Pläne zu verifizieren. Spannend ist vor allem die Frage, wie viel praktisch getestet werden kann und wie viel davon in einer realen Umgebung, also unter Produktionsbedingungen. Jede Art von Test wird für ein bestimmtes Maß an Gewissheit sorgen. Es ist notwendig, für jedes betrachtete Schadensszenario zu bestimmen, welche Art von Test hilft, das jeweils nötige Maß an Gewissheit zu erreichen. Nicht in jedem Fall ist ein praktischer Test in der produktiven Umgebung zwingend nötig. Manchmal reicht ein Test in einer Testumgebung, manchmal ein simulierter Test am Schreibtisch („Table-Top-Übung”), manchmal ein Review des Notfallhandbuchs durch einen unabhängigen Fachmann. Die aus Sicht der Beteiligten, Systemspezialisten wie Notfallbeauftragter, angemessene Strategie soll als Testplan beschrieben werden, und zwar unabhängig von der Frage, ob ein solcher Test durchführbar ist. In Spalte 6A wird überwacht, ob es einen aktuellen Testplan gibt.
Auf Widersprüche unnachgiebig hinweisen!
Natürlich wird es in vielen Fällen an verfügbarem Budget und anderen wichtigen Ressourcen für Tests mangeln. Testsysteme sind teuer und Time Slots für die Tests schwer zu finden. Manchmal sind praktische Tests auch aus technischen Gründen kaum möglich oder mit einem unverantwortlich hohen Risiko verbunden, z. B. im Rechenzentrum einer Klinik. Dann können eigentlich als notwendig erachtete Tests nicht durchgeführt werden. Die Folge wird sein, dass die Gewähr sinkt, dass der Plan im Notfallhandbuch funktionieren würde, wenn er gebraucht wird. Ist das akzeptabel? Das ist eine Bewertung, für die es eine Metrik geben muss. Unter dieser Bedingung wird eine Aussage der Art „Verlässlichkeit des Notfallhandbuchs: zu gering” zu einem Fakt (vgl. Tabelle 5, Spalte 5D). Auch wenn begründet werden kann, warum ein an sich nötiger Test nicht durchgeführt wurde, macht das die Angelegenheit nicht weniger problematisch. Das Controlling soll auf solche Widersprüche hinweisen.
Natürlich wird es in vielen Fällen an verfügbarem Budget und anderen wichtigen Ressourcen für Tests mangeln. Testsysteme sind teuer und Time Slots für die Tests schwer zu finden. Manchmal sind praktische Tests auch aus technischen Gründen kaum möglich oder mit einem unverantwortlich hohen Risiko verbunden, z. B. im Rechenzentrum einer Klinik. Dann können eigentlich als notwendig erachtete Tests nicht durchgeführt werden. Die Folge wird sein, dass die Gewähr sinkt, dass der Plan im Notfallhandbuch funktionieren würde, wenn er gebraucht wird. Ist das akzeptabel? Das ist eine Bewertung, für die es eine Metrik geben muss. Unter dieser Bedingung wird eine Aussage der Art „Verlässlichkeit des Notfallhandbuchs: zu gering” zu einem Fakt (vgl. Tabelle 5, Spalte 5D). Auch wenn begründet werden kann, warum ein an sich nötiger Test nicht durchgeführt wurde, macht das die Angelegenheit nicht weniger problematisch. Das Controlling soll auf solche Widersprüche hinweisen.
11 Berichte
Viele Personen wirken an der IT-Notfallvorsorge mit. Manche wie die Mitarbeiter der Fachbereiche müssen selbst aktiv werden, zum Beispiel an Dokumenten arbeiten und Übungen durchführen. Manager müssen einschreiten, wenn das nicht passiert. Zudem vertreten sie das Unternehmen oder ihren Bereich nach außen. Jedenfalls sollten sie wissen, was in ihm vorgeht.
Berichtswesen ist ein mächtiges Instrument
Der Notfallbeauftragte ist so etwas wie der Diener der IT-Notfallvorsorge. In ihrem Auftrag muss er alle, die hierbei Aufgaben und Pflichten zu erfüllen haben, immer wieder erinnern, diese zu erfüllen. Dazu sollte er ein geordnetes Berichtswesen einrichten. Das ist nicht nur eine lästige Pflicht. Der Notfallbeauftragte verfügt damit über ein mächtiges Instrument, um die Interessen der IT-Notfallvorsorge zu fördern, indem er den Fokus auf die Missstände legt, die aus seiner Sicht nicht akzeptabel sind.
Der Notfallbeauftragte ist so etwas wie der Diener der IT-Notfallvorsorge. In ihrem Auftrag muss er alle, die hierbei Aufgaben und Pflichten zu erfüllen haben, immer wieder erinnern, diese zu erfüllen. Dazu sollte er ein geordnetes Berichtswesen einrichten. Das ist nicht nur eine lästige Pflicht. Der Notfallbeauftragte verfügt damit über ein mächtiges Instrument, um die Interessen der IT-Notfallvorsorge zu fördern, indem er den Fokus auf die Missstände legt, die aus seiner Sicht nicht akzeptabel sind.
Zwei Typen von Berichten sind zu unterscheiden.
KVP
Es gibt einerseits Berichte, die helfen sollen, Dinge voranzutreiben und Verbesserungen herbeizuführen. In einem Managementsystem ist das Teil des Prozesses der kontinuierlichen Verbesserung (KVP). Berichte des KVP werden eher die schlechten Nachrichten betonen. Mängel etwa werden beschrieben, um das Mandat zu bekommen, sie abstellen zu dürfen bzw. jemand anderen dazu anhalten zu dürfen. Vom Berichtsempfänger wird erwartet, dass er dafür die nötigen Mittel bereitstellt und Kompetenzen gewährt – oder die Verantwortung dafür übernimmt, dass am Status quo nichts geändert wird.
Es gibt einerseits Berichte, die helfen sollen, Dinge voranzutreiben und Verbesserungen herbeizuführen. In einem Managementsystem ist das Teil des Prozesses der kontinuierlichen Verbesserung (KVP). Berichte des KVP werden eher die schlechten Nachrichten betonen. Mängel etwa werden beschrieben, um das Mandat zu bekommen, sie abstellen zu dürfen bzw. jemand anderen dazu anhalten zu dürfen. Vom Berichtsempfänger wird erwartet, dass er dafür die nötigen Mittel bereitstellt und Kompetenzen gewährt – oder die Verantwortung dafür übernimmt, dass am Status quo nichts geändert wird.
Compliance
Andererseits gibt es Berichte, bei denen es das Hauptziel ist nachzuweisen, dass die IT-Notfallvorsorge auf gutem Weg ist. Gewöhnlich passiert das im Kontext von Compliance, worunter die Einhaltung von Vorschriften, vorrangig von Gesetzen, aber auch von Verträgen, Normen oder ganz generell der Strategie des Unternehmens, zu verstehen ist. Wo die IT-Notfallvorsorge zu Compliance verpflichtet ist, muss sie belegen können, dass sie die betreffenden Regeln einhält. Dies erfolgt zum Beispiel gegenüber der Geschäftsführung und ihr nahestehenden Aufsichtsorganen wie der Revision oder dem Risk Management, gegenüber Auditoren oder Kunden, aber auch gegenüber dem Information Security Officer. Inhalt, Form und Häufigkeit diesbezüglicher Berichte sollten vom Empfänger festgelegt werden. Wo dies nicht der Fall ist, wird der Notfallbeauftragte Vorschläge machen müssen.
Andererseits gibt es Berichte, bei denen es das Hauptziel ist nachzuweisen, dass die IT-Notfallvorsorge auf gutem Weg ist. Gewöhnlich passiert das im Kontext von Compliance, worunter die Einhaltung von Vorschriften, vorrangig von Gesetzen, aber auch von Verträgen, Normen oder ganz generell der Strategie des Unternehmens, zu verstehen ist. Wo die IT-Notfallvorsorge zu Compliance verpflichtet ist, muss sie belegen können, dass sie die betreffenden Regeln einhält. Dies erfolgt zum Beispiel gegenüber der Geschäftsführung und ihr nahestehenden Aufsichtsorganen wie der Revision oder dem Risk Management, gegenüber Auditoren oder Kunden, aber auch gegenüber dem Information Security Officer. Inhalt, Form und Häufigkeit diesbezüglicher Berichte sollten vom Empfänger festgelegt werden. Wo dies nicht der Fall ist, wird der Notfallbeauftragte Vorschläge machen müssen.
Prozessübersicht
Der Notfall-Monitor kann selbst dann, wenn er technisch einfach gehalten wird, vollautomatisch Berichte erzeugen und die Fakten und Bewertungen zielgerecht und ansprechend präsentieren. Dafür folgen nun einige Beispiele. Abbildung 3 zeigt, wie der Gesamtstatus des Prozesses der IT-Notfallvorsorge visualisiert werden kann.
Der Notfall-Monitor kann selbst dann, wenn er technisch einfach gehalten wird, vollautomatisch Berichte erzeugen und die Fakten und Bewertungen zielgerecht und ansprechend präsentieren. Dafür folgen nun einige Beispiele. Abbildung 3 zeigt, wie der Gesamtstatus des Prozesses der IT-Notfallvorsorge visualisiert werden kann.

KPIs
Ein wichtiger Teil von Management Reports sind Aussagen zu den sogenannten Key Performance Indicators (KPIs), also Kennzahlen, mit denen die Qualität der IT-Notfallvorsorge gemessen wird. Was ein KPI der IT-Notfallvorsorge ist, muss individuell vereinbart werden. In Abbildung 4 wird gezeigt, wie eine Grafik für den Fall aussehen könnte, dass die Qualität der IT-Notfallvorsorge (auch) daran gemessen wird, wie aktuell die Notfallpläne sind.
Ein wichtiger Teil von Management Reports sind Aussagen zu den sogenannten Key Performance Indicators (KPIs), also Kennzahlen, mit denen die Qualität der IT-Notfallvorsorge gemessen wird. Was ein KPI der IT-Notfallvorsorge ist, muss individuell vereinbart werden. In Abbildung 4 wird gezeigt, wie eine Grafik für den Fall aussehen könnte, dass die Qualität der IT-Notfallvorsorge (auch) daran gemessen wird, wie aktuell die Notfallpläne sind.

Abbildung 5 präsentiert den gleichen KPI, jedoch diesmal tabellarisch in einer Trendaussage: Hat sich die Situation seit dem letzten Bericht verbessert oder nicht?

Berichtsform abstimmen
Schwieriger als die automatisierte Generierung von Berichten dürfte es sein, sich mit den Berichtsempfängern darauf zu verständigen, welche Informationen die Berichte enthalten sollen. Oft wird der Notfallbeauftragte dazu Vorschläge machen müssen, da er am besten weiß, wie der Status kompakt und aussagekräftig dargestellt werden kann.
Schwieriger als die automatisierte Generierung von Berichten dürfte es sein, sich mit den Berichtsempfängern darauf zu verständigen, welche Informationen die Berichte enthalten sollen. Oft wird der Notfallbeauftragte dazu Vorschläge machen müssen, da er am besten weiß, wie der Status kompakt und aussagekräftig dargestellt werden kann.
12 Fazit
Das Controlling, also die Steuerung aller Teilaufgaben der IT-Notfallvorsorge, ist weder besonders kompliziert noch arbeitsaufwändig, sofern das Unternehmen dafür einige Vorbereitungen getroffen hat:
| • | Der Prozess der IT-Notfallvorsorge ist beschrieben worden. Es ist also bekannt, was im Rahmen der IT-Notfallvorsorge zu tun ist, wessen Aufgabe das ist und was die Einzelschritte jeweils liefern sollen. |
| • | Es gibt eine straffe Metrik für die Bewertungen des Status der geforderten Arbeitsergebnisse. |
| • | Es gibt einfache Werkzeuge zur Erfassung von Fakten und zur Dokumentation von Bewertungen („Notfall-Monitor”). |
| • | Die Handhabung von Standardaufgaben einer IT-Organisation, zum Beispiel die Nachverfolgung von Maßnahmen und Aufgaben, ist geregelt. |
| • | Es gibt ein System für das Dokumentenmanagement, das die Anforderungen einer IT-Notfallvorsorge erfüllt. Das umfasst ein Ablagesystem für alle Notfalldokumente. |
| • | Es gibt einen Notfallbeauftragten – auch wenn er vielleicht anders heißt. |
Aufwand für Aufbau
Der Aufbau eines solchen Systems muss kein Riesenprojekt sein. Aufwand wird es vor allem bei der Feinabstimmung der geforderten Metriken geben. Auch wenn eine Metrik letztlich nur aus wenigen Werten und den zugehörigen Erläuterungen bestehen wird, kann es ein langer Weg sein, um zu diesem Resultat zu gelangen.
Der Aufbau eines solchen Systems muss kein Riesenprojekt sein. Aufwand wird es vor allem bei der Feinabstimmung der geforderten Metriken geben. Auch wenn eine Metrik letztlich nur aus wenigen Werten und den zugehörigen Erläuterungen bestehen wird, kann es ein langer Weg sein, um zu diesem Resultat zu gelangen.
Aufwand für Betrieb
Der Aufwand für den Betrieb des Controllings ist gering. Erwähnenswert wird am ehesten der Aufwand für das sein, was das Controlling anstoßen wird. Einen Missstand zu erkennen wird nicht mehr das Problem sein, aber die Lehren daraus zu ziehen und angemessene Maßnahmen einzuleiten und umzusetzen kann viel Arbeit sein.
Der Aufwand für den Betrieb des Controllings ist gering. Erwähnenswert wird am ehesten der Aufwand für das sein, was das Controlling anstoßen wird. Einen Missstand zu erkennen wird nicht mehr das Problem sein, aber die Lehren daraus zu ziehen und angemessene Maßnahmen einzuleiten und umzusetzen kann viel Arbeit sein.
Die wichtigen Liefereinheiten des Prozesses der IT-Notfallvorsorge sind:
| • | Servicesteckbrief |
| • | Business Impact Analysis |
| • | Risikoanalyse |
| • | Notfallhandbuch inklusive Continuity Plans und Recovery Plans |
| • | Testplan und Testbericht |
Es war nicht Ziel dieses Beitrags, zu beschreiben, wie diese Dokumente aussehen sollen und wie sie gepflegt werden. Das kann, je nach Aufstellung des Unternehmens, eine einfache oder auch sehr komplexe Lösung sein. Jedoch lassen sich auch dafür sowohl Lösungen aufbauen, die selbst kleinste IT-Organisationen nicht überfordern, als auch solche, die den Anforderungen in großen Unternehmen angemessen sind.
Quellen
1
DIN EN ISO 22301:2020 – Sicherheit und Resilienz – Business Continuity Management System – Anforderungen; Deutsch Fassung. Englischer Originaltitel: ISO 22301:2019 – Societal security – Business continuity management systems – Requirements
